
By Ryan Scrivens, Joshua D. Freilich, Steven M. Chermak, and Richard Frank
Click to read this article in French and German.
The role of the Internet in facilitating violent extremism and terrorism is a primary concern for many researchers, practitioners, and policymakers around the world. The so-called Islamic State, an internationally designated terrorist organization, released a steady stream of video-recorded beheadings of Western hostages and other atrocity footage to radicalize some while intimidating others. Violent anti-fascist extremists used social media to instigate widespread violence against law enforcement during COVID-19 lockdowns and following George Floyd’s killing. Many of the right-wing extremists who engaged in violence during the January 6th Capitol Riot also used online channels to coordinate and/or boast about their involvement. Understandably, law enforcement and intelligence communities have become invested in examining the digital footprints of violent extremist movements. It also comes as no surprise that online terrorism and extremism research has grown rapidly in recent years, with a variety of data collection techniques emerging to address key research questions in the space. The primary focus of this effort has been on extracting open-source, publicly available information from active data sources (e.g., social media platforms, websites, blogs, forums) and informative sources (e.g., online newspapers, government reports, existing databases).
As studies in this research area have increased, various data collection techniques have emerged to address key research questions, ranging from manual extraction to computational tools to collect online information. Yet despite the growing efforts in online terrorism and extremism research to collect open-source information, little is known about the methodological, practical, and ethical challenges of open-source data collection in this research space particularly or in terrorism and extremism studies generally. Instead, what we generally know comes from studies that briefly highlight limitations specific to a project or a particular research method.
In our forthcoming article in the special issue “The strengths and struggles of different methods of research on radicalization, extremism and terrorism” in Studies in Conflict & Terrorism, edited by Frank Weerman and Elanie Rodermond, we examine key strengths, limitations, and ethical concerns associated with open-source data collection methods commonly used in online terrorism and extremism research. The purpose of this article is to assist researchers and analysts in choosing between commonly used data collection methods in this regard, as is summarized in Table 1.
Table 1. Strengths and limitations of data collection methods in online terrorism and extremism research.
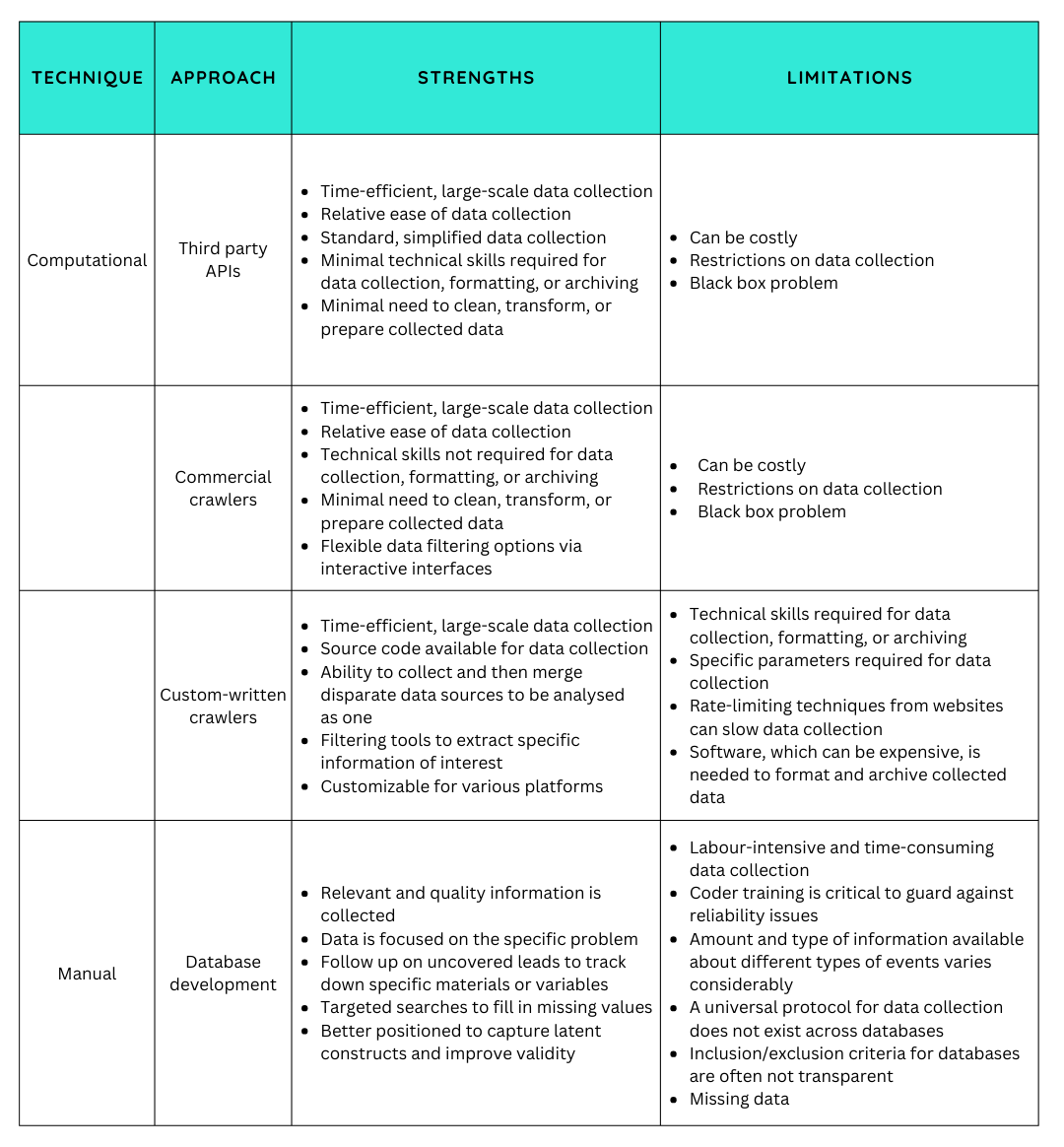
Importantly, the article also sets forth suggestions for progressing data collection efforts in online terrorism and extremism research based on the methods highlighted above, which is the focus of this blog post. By no means, however, do we provide suggestions based on every study on, or trend in, data collection in online terrorism and extremism research. Instead, our suggestions are derived from what we view as key current and emerging trends from our involvement in the field. We have contributed to the expansion of online terrorism and extremism research, from developing computational tools for large-scale extraction and analysis of extremist content online at the International CyberCrime Research Centre, to creating the open-source database U.S. Extremist Cyber Crime Database to better understand online pathways to radicalization and mobilization. These experiences have provided us with unique insights regarding the usefulness of various open-source data collection efforts in online terrorism and extremism research and avenues for future work.
First, combining data extraction techniques in online terrorism and extremism research, such as blending manual and automated data extraction techniques or linking commercial crawlers with other data extraction tools, will advance research in this space. These combinations, although relatively rare in the online terrorism and extremism literature, have shown signs of success, in part because a technical background is not required for data collection, and because researchers can draw from the abovementioned strengths of each extraction technique. Combining techniques will also help researchers better understand what is captured and what is missing using different strategies as well as identify areas where adjustments in the process should be made. In addition, combining techniques may be helpful in addressing some of the more challenging aspects of data collection in contemporary online terrorism and extremism research, such as identifying and then collecting image and video-based content from online sharing apps such as Instagram and TikTok or from encrypted communication apps such as Telegram and Signal, or even from gaming platforms such as Steam and Twitch. Here, violent extremist content, users, or networks of interest could be manually identified from these platforms and then the data extracted using computational techniques.
Second, future data collection efforts would benefit from the integration of traditional methods (e.g., in-depth interviews or surveys) with computational methods to address key research questions with policy implications. Scrivens and colleagues, for example, used a customized web-crawler to extract online content from a sample of violent and non-violent right-wing extremists who were identified by a former violent extremist during an in-depth interview. Here the researchers were in a unique position to identify which online users engaged in violent extremism offline to explore an array of their online behaviours compared to their non-violent counterpart. Such an open-source dataset containing users’ offline violent behaviour is indeed rare in online terrorism and extremism research, as most drawing from open-source data simply do not have access to ground truth. This is a main limitation of open-source data generally, and not only in terrorism and extremism research, because developing a high level of confidence in the accuracy of second-hand information is challenging without first-hand collection of such data.
Third, researchers must make archives of the extremist online content accessible for other researchers. Access to data in online terrorism and extremism research remains a challenge for many in the field, especially junior and early career scholars who may not have the resources or skillsets. This is despite the various calls from researchers to make such content more widely available for research purposes. Surprisingly, to date only a small number of individuals have contributed to this initiative. The Dark Web Project, for example, collected and made available the content of 28 jihadi forums comprising over 13 million messages. The Dark Crawler database includes, but is not limited to, over 11 million posts from the most conspicuous right-wing extremist forum, Stormfront; over 8 million posts that include Islamist content; as well as over 49 million posts drawn from 11 right-wing extremist subreddits – all are available to users for research upon request. Not only are these exceptional databases few and far between, these two resources have not been widely used by researchers, perhaps because they are less known compared to widely used databases such as the Global Terrorism Database. Regardless, providing researchers with access to non-traditional data sources, especially open-source intelligence and social media data, will undoubtably transform the future understanding of violent extremism and terrorism in general and online terrorism and extremism in particular.
Lastly, in addition to collecting and then sharing open-source data among key stakeholders generally, those working in online terrorism and extremism research should triangulate data across databases and datasets. Taking a lead in this respect are, for example, Holt, Freilich, Chermak, and LaFree, who triangulated data between the Extremist Crime Database and the Profiles of Individual Radicalization in the United States database, testing whether various criminological theories account for on- and offline pathways to extremist violence. This provided multiple observational points to explore the similarities and differences across offenders’ background, attitudes, and behaviour. Perhaps equally valuable would be for researchers to merge such databases with databases that include extremist online content, such as the abovementioned Dark Web Project and The Dark Crawler databases, and to develop a central database in which various online platforms that violent extremists and terrorists have been known to frequent can be made available in one space. This would place researchers in a better position to explore key questions in online terrorism and extremism research, such as whether consumption of violent extremist online content lead directly to violent acts occurring that would not have occurred if the Internet did not exist.
Ryan Scrivens is an Assistant Professor in the School of Criminal Justice at Michigan State University (MSU), an Associate Director at the International CyberCrime Research Centre (ICCRC), and a Research Fellow at VOX-Pol. Follow him on X: @R_Scrivens.
Joshua D. Freilich is a Professor in the Criminal Justice Department and the Criminal Justice PhD program at John Jay College, CUNY.
Steven M. Chermak is a Professor in the School of Criminal Justice at MSU. Follow him on X: @s_chermak.
Richard Frank is a Professor in the School of Criminology at Simon Fraser University and the Director of the ICCRC. Follow the ICCRC on X: @ICCRC_SFU.
Image credit: Unsplash