
This is the third in a series of four original Blog posts; the first is HERE and the second is HERE. [Ed.]
By Matti Pohjonen
The previous blog posts looked at the costs and benefits of using network analysis to identify extremist networks. It suggested that one challenge in such network analysis-based research approaches is the difficulty of interpreting what the powerful network visualisations and statistics mean, especially when lacking deeper domain knowledge of the context behind them. One way to mitigate this problem is complementing network-based approaches with more mixed methods approaches, such as combining it with interviews, digital ethnography, or content analysis.
This post considers research approaches developed to analyse extremist content. This loosely refers to a broad range of computational methods developed to transform the messy world of online and social media communication (such as tweets, posts, or comments) into a numerical form, which then allows different types of statistical analyses to be carried out. Historically, the focus of such content-based approaches has been predominantly on textual content, but advances in especially deep learning-based computer vision have now also made image- and video-based approaches increasingly feasible for researchers.
There are many techniques available for researchers who are interested in extracting insights from the abundant content produced and shared online and on social media. Typically this takes place by first reducing the dimensionality of the content through reducing grammatical diversity or removing words that have no semantic value. Once the dimensionality of the data is reduced through techniques such as the bag-of-words model (or, in the case of images, through convolution operations), various statistical techniques can be applied to this content to gain more granular insights into the topics, themes, and sentiment expressed in it.
This includes both simpler techniques, such as frequency analysis or word associations, as well as more computationally complex techniques such as topic models or word embeddings. In the case of visual data, advancements in computer vision also allow research to extract insights from images or video with increasing accuracy, such as finding similar images, detecting objects in the images, or even exploring the sentiment of the people present in the images.
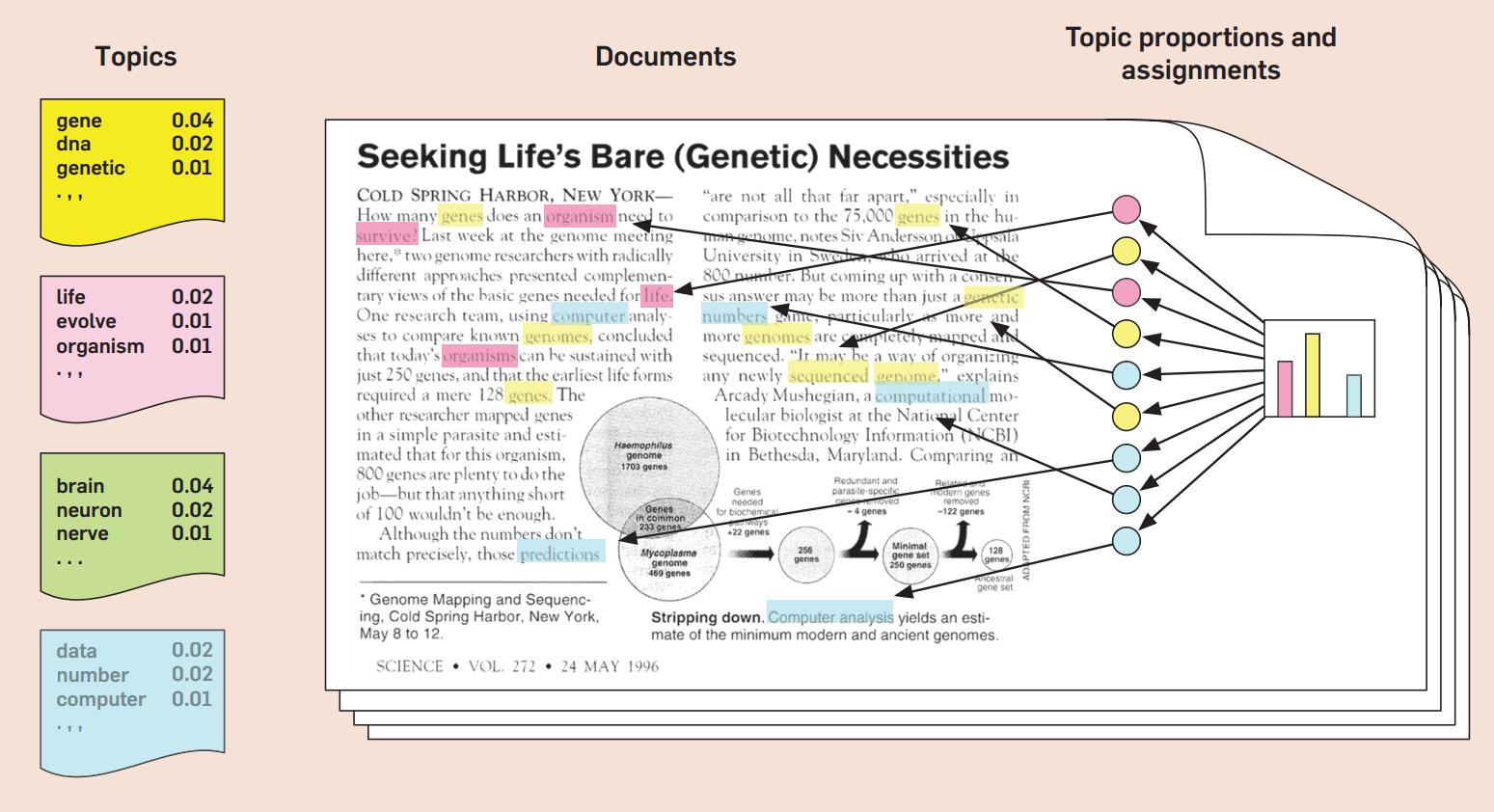
Overview of methods used in online extremism research
Building on advancements in Natural Language Processing (NLP) and computer vision, researchers interested in online extremism have applied such content-based research approaches to identify and extrapolate different insights from online or social media content.
This includes approaches such as classifying the content based on the prevalence of themes such as hate speech or misinformation or using topic models to discover extremist themes and topics in large-scale textual datasets.
Another popular set of approaches has explored the use of different types of sentiment analysis to classify extremist conversations based on sentiment expressed in them. This is commonly done through assigning social media posts or comments a sentiment value depending on whether it contains negative, neutral, or positive sentiment words. Such sentiment analysis is facilitated by using existing sentiment dictionaries or corpora or by machine learning models available to researchers from both open-source and commercial sources (e.g. such as Stanford NLP or NLTK or commercial services such as Google ML, which allow researchers to access the power of state-of-the-art language models with relatively little effort).
Most of the existing computational or big data methods used in extremism research have focused on textual content, but new approaches in computer vision have also made visual (and audio-visual) content analysis increasingly feasible for researchers. State-of-the-art techniques using computer vision can extrapolate visual similarities between images to identify relevant images in large datasets (e.g. such as the use of hashing of images to aid the removal of extremist content from social media). Other approaches have been developed to identify different types of visual content based on the objects found in it or the sentiment expressed (e.g. identifying different types of objects or detecting emotional valence in large-scale visual data).

Even if such visual research remains experimental and challenging to instrumentalise for online extremism research, computer vision is one of the most rapidly advancing fields of computational content analysis. As more and more online communication becomes visual, the increasingly sophisticated use of visual analysis is expected to open up interesting new research possibilities for even non-technical extremism researchers.
Cost-benefit analysis
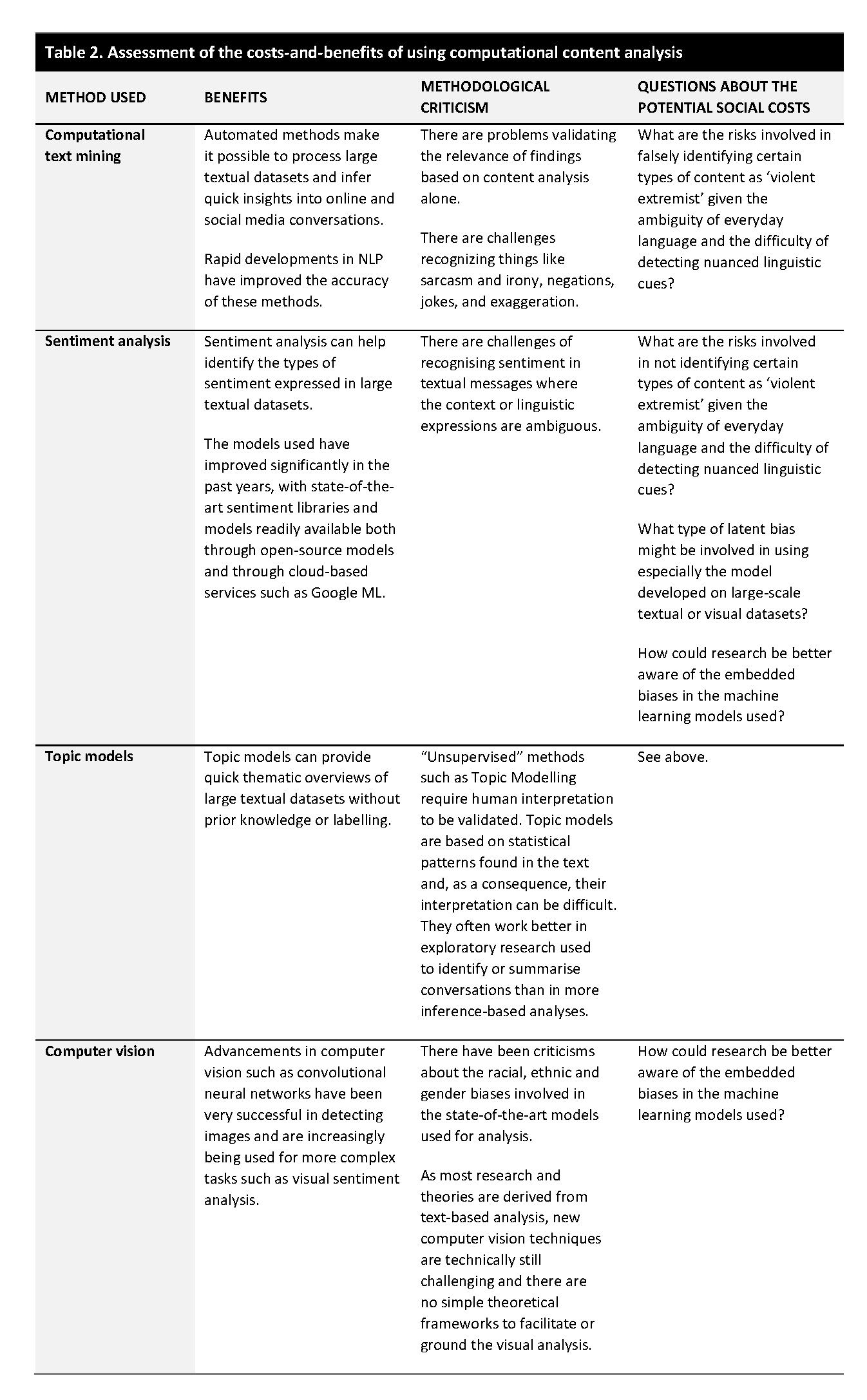
The many powerful methods available to identify and analyse extremist content online and on social media have been applied to a diverse range of research problems. Despite the popularity of the different approaches available, especially for text-based analysis, there have also been criticisms raised about the methodological validity and the potential negative social costs involved in their use.
The methodological criticisms are broadly that such content-based approaches work well when the research focus is highly specific and there are clear definitions of the key concepts and terms to anchor the analysis (e.g. such as identifying clear examples of violent extremist content, which have little linguistic ambiguity). Real-world examples of extremist communication, however, seldom display precise conceptual definitions and instead involve ambiguous language that changes and evolves. As a result, researchers can face challenges in identifying exactly what types of features can be used to validate the analysis (e.g. what linguistic markers are sufficiently representative of extremist communication).
Even the best tools commonly used fall short of the human ability to understand language because of the widespread use of metaphors, irony, sarcasm, and other linguistic tropes characteristic of human communication in a situation where even human annotators often struggle to reach sufficient intercoder reliability regarding the key terms used. This has raised questions about the overall validity of such approaches in situations where every research problem requires a new dataset to be trained independently. This can be a resource-intensive and time-consuming task especially for researchers with limited resources, but it also risks the models used being too ambiguous and detecting examples that are not appropriate to the research task at hand.
Critics have also argued that computational or big data methods used to analyse extremist content can further exacerbate negative social costs especially if they reproduce the implicit social biases embedded into the legacy datasets used in these methods. This is because many of the state-of-art models in both text and image-based content analysis build on models trained on massive datasets (e.g. such as the BERT model for linguistic analysis or ImageNet for computer vision).
The training data used in these AI models unavoidably also include the latent historical biases embedded into the training data, however. Research has noted that using machine learning for content analysis can thus embed the latent gender, ethnic, or racial biases in these datasets, which can indirectly influence the analysis. As a result, decisions based on the methods used can amplify the marginalisation of groups because of the biases in the training data used. Moreover, many of the state-of-the-art models in use have been developed for major European languages, especially English, only. So, despite improvements, use of these methods outside the Western context is often challenging, which can make it difficult for researchers to identify extremist groups that use languages not adequately covered in existing machine learning approaches.
One possible way to mitigate these challenges would be to bring in more mixed methods or qualitative approaches to curate the data to ensure that the lexicons used are representative of the extremist activity in question. Another approach involves working with critical AI researchers to make sure that the models used are debiased, that is, the data that the models are trained on is heterogeneous enough to avoid exacerbating latent social or political biases, especially when dealing with vulnerable communities.
Such detective work, however, can be challenging to especially social science researchers who do not have sufficient resources or technical acumen to explore the complex ethical debates involved in training machine learning or AI models. This is something that, at the least, is good to be aware of when thinking about these models implementation in practical research situations. There are also good resources such as FatML algorithms that can aid in this.
Matti Pohjonen is a Researcher for a Finnish Academy-funded project on Digital Media Platforms and Social Accountability (MAPS) as well as a VOX-Pol Fellow. He works at the intersection of digital anthropology, philosophy and data science. On Twitter @objetpetitm.
Previously in the Series:
Part I: A Framework for Researchers
Part II: Identifying Extremist Networks
Next in the series:
Part IV: Predicting Extremist Behaviour